Blog
News, updates and analysis
Based on your feedback and requests, we've reshuffled the model lineup across subscription tiers — to make more useful models available right away without a subscription, and to give BASIC subscribers noticeably more options to work with. Big thanks to everyone who wrote in via support and Discord — this update is built directly from your suggestions.
Now available in FREE
- MIND — formerly BASIC
- OPEN — formerly BASIC
Even without a subscription, you now have two additional models with different decision logic, ready to try on upcoming matches.
Added to BASIC
- ELO — moved up from FREE
- WR10COMBO — moved up from FREE
- WR10, PHANTOM, APEX, STREAK, ORACLE — moved down from PRO
Five additional models that previously required PRO are now open to BASIC subscribers too.
What this means for you
- If you're on PRO: nothing changes — every model on the site is still available to you.
- If you're on BASIC: you now have 5 more models in your toolkit (WR10, PHANTOM, APEX, STREAK, ORACLE).
- If you're on FREE: MIND and OPEN are now yours — try them on the next few matches and see how they pick.
See the full lineup per tier on the Models leaderboard. Keep the feedback coming — it genuinely shapes how we develop the site.
We're rolling out a new section on CS2PREDICT: Pickem Predictions. Each CS2 Major has an Pickem Challenge — pick the team that goes 3-0, the team that goes 0-3, and the 7 teams that advance through the Swiss stage. Max 15 points (4 + 4 + 7). Hundreds of thousands of fans play it every Major. Now you can see what AI thinks before locking in your own pick.
What's live now: IEM Cologne Major 2026 — Stage 1
The Stage 1 (Challengers) page is up: /pickem/iem-cologne-major-2026-stage-1/
- AI Consensus — a quick "which team has the most model votes" view for each of the 9 Pickem slots. Pick the consensus choice if you want the safe play.
- Per-Model Picks — 27 AI models, each running 10,000 Monte Carlo simulations of the Swiss bracket and choosing its own 3-0/0-3/advance picks based on its match-level priors. Models ranked by their top-tier historical accuracy.
- Per-model deep-dive — click any model card to see the full 16-team probability matrix and confidence bars for that model's picks.
Coming soon: Stage 2 (Legends)
Stage 2 — the Legends stage with the 8 invited top-seeds joined by the 8 Stage-1 advancers — gets its own Pickem page as soon as the field is finalized on HLTV. Same format: AI consensus on top, per-model breakdown below. Watch this space.
What's next: user Pickem contest
We're planning a community Pickem challenge right alongside the AI: log in, submit your own 9 picks, and compete against the 27 models after the Major wraps. Final leaderboard will show user scores intermixed with AI scores — beat the algorithms and prove your CS2 sense.
Details (sign-up, prizes, timing) coming in a follow-up post. If you want a heads-up when entries open, log in and watch the Pickem section.
How AI predicts the Swiss bracket
Each model has its own per-match win-probability logic (ELO, recent form, head-to-head, tactical metrics). For Pickem we run 10,000 Monte Carlo simulations of the full 16-team Swiss bracket per model — every potential pairing flipped by a biased coin weighted by that model's match-level probability. The 3-0 pick = the team that finished without a loss most often, 0-3 = the team that finished winless most often, advance = top-7 by P(3-1 ∪ 3-2).
The simulation re-runs every time Cologne's seeding or team-strength data changes, until lock time (24h before the first Swiss match).
Weekly leaderboard · Week 20 results (May 11 – May 17, 2026) · published Week 21
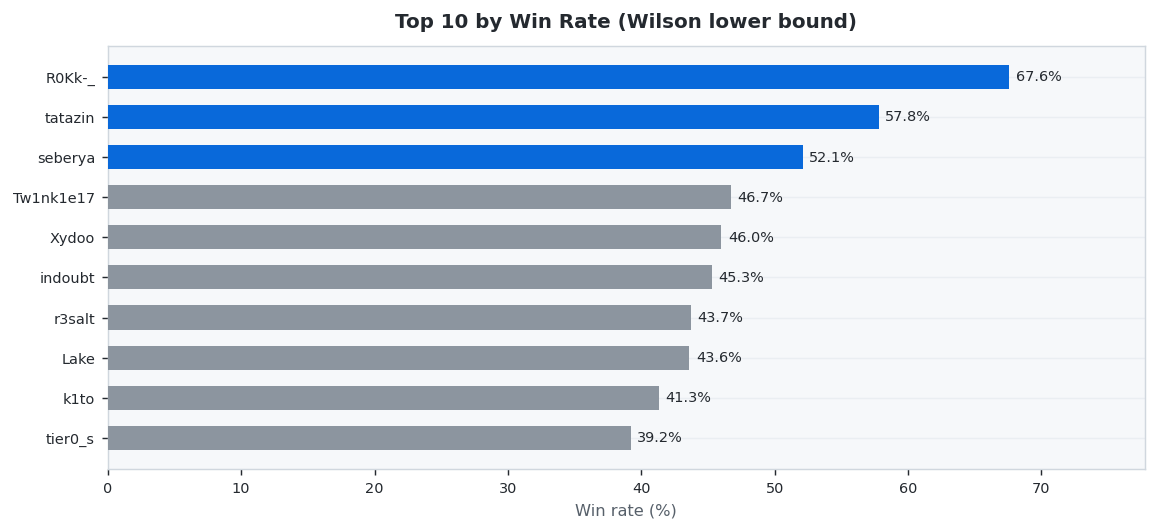
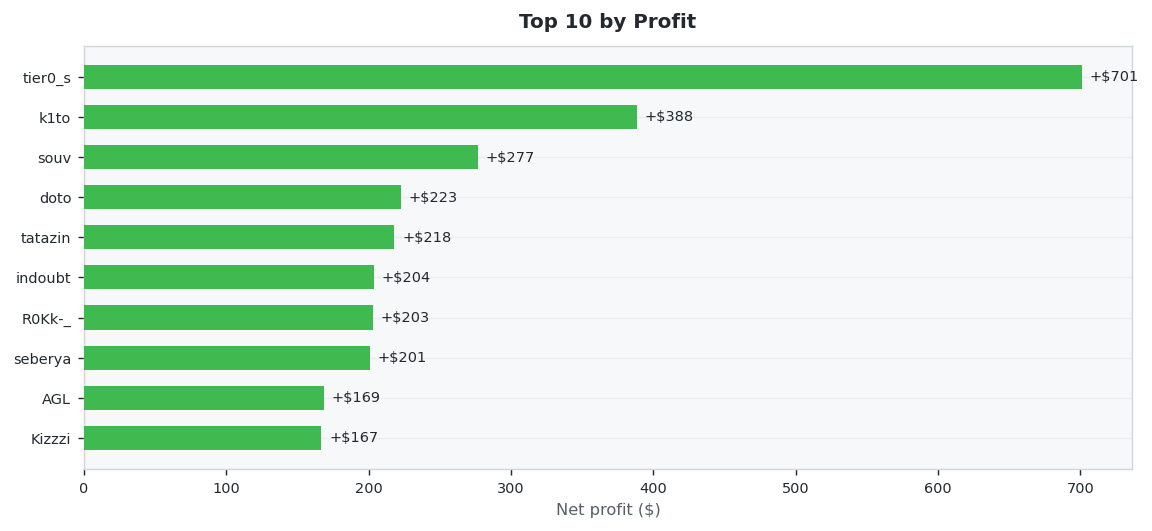
47 predictors placed 647 settled wagers this week (Week 20 results (May 11 – May 17, 2026) · published Week 21). R0Kk-_ led on accuracy at 67.6% Wilson, while tier0_s netted +$701.30 in profit. Average accuracy across the field: 26.5%.
🎯 Win Rate Champion
Highest accuracy by Wilson lower bound (3+ settled wagers required to qualify).
💵 Profit Champion
Highest net USD return (winnings minus stakes). Green bars are winners, red are net losers.
Want next week's prize?
Top-1 in each category wins +$20. Place 3+ predictions on the match list · check the live leaderboard.
Weekly digest · Top-tier CS2 matches · Week 21 · May 11 – May 17, 2026
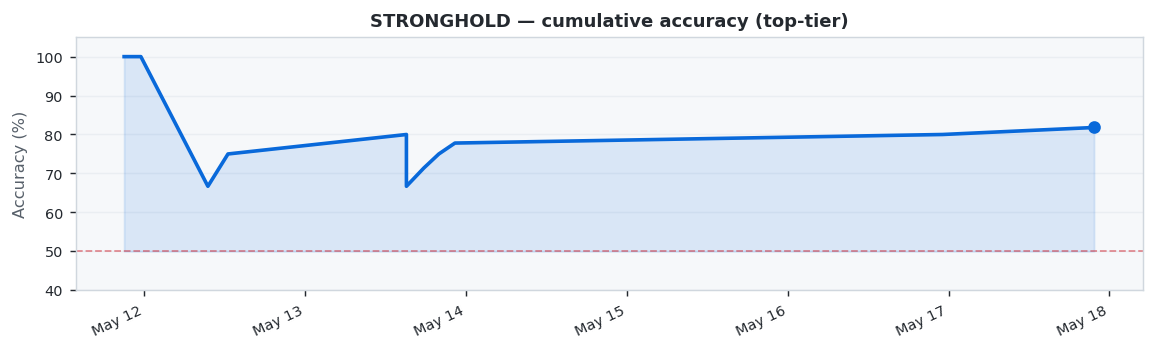
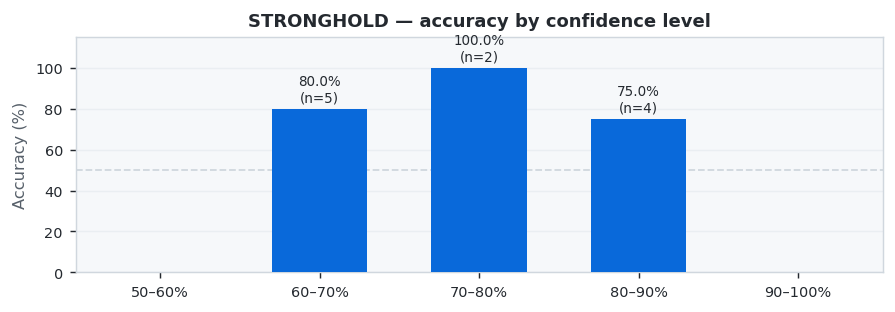
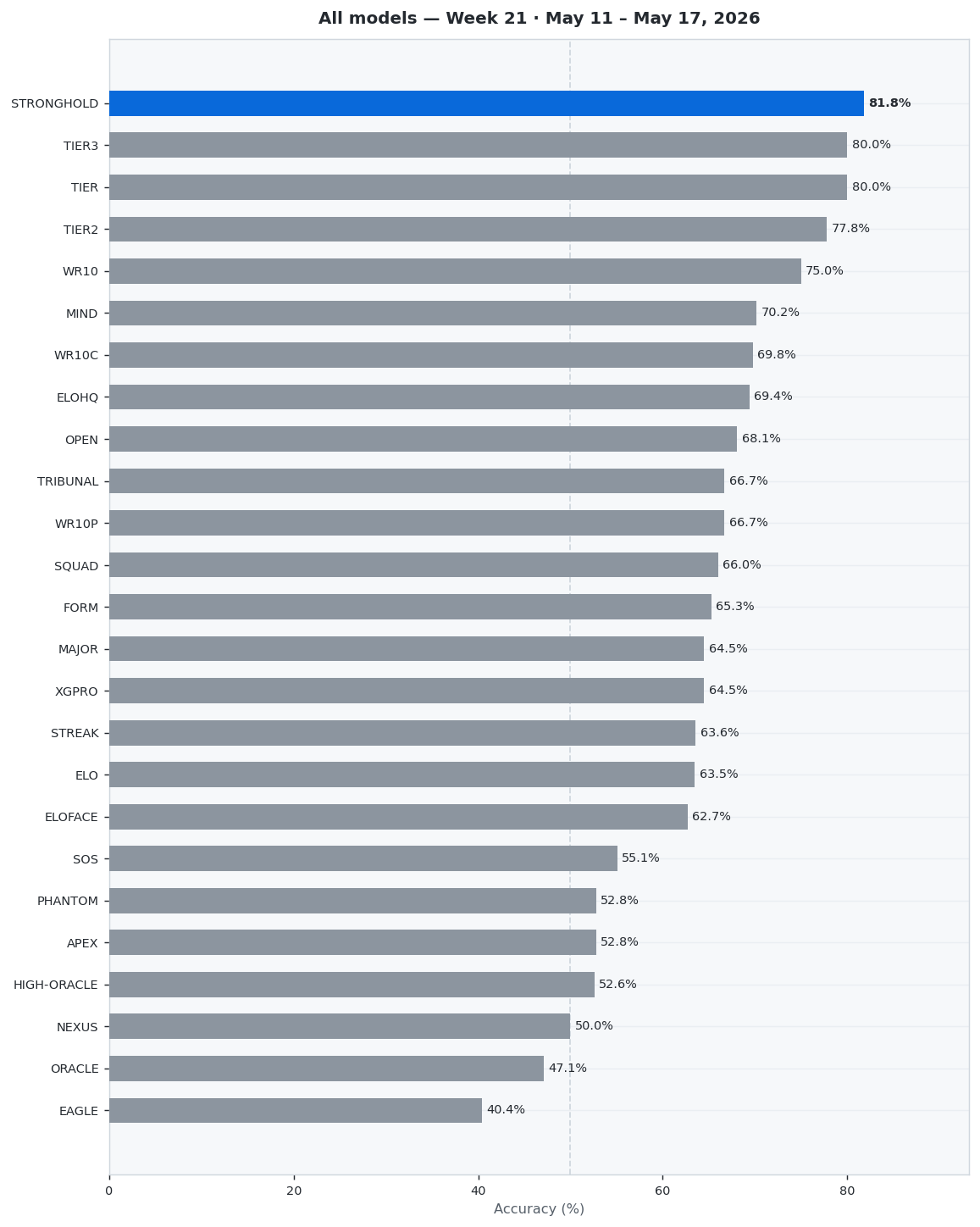
This week (Week 21 · May 11 – May 17, 2026) we analyzed 57 top-tier CS2 matches across 25 prediction models. STRONGHOLD dominated with 81.8% accuracy (9/11 correct), ahead of TIER at 80.0%. STRONGHOLD achieved a Brier Score of 0.1542 and Log Loss of 0.4943.
🏆 Model of the Week: STRONGHOLD
STRONGHOLD had an outstanding week, correctly predicting 9 out of 11 matches.
STRONGHOLD showed excellent performance with 81.8% accuracy across 11 predictions (9 correct, 2 wrong).
📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.
🎮 STRONGHOLD Predictions This Week
9/11 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| GamerLegion 0-3 Natus Vincere | 68% Natus Vinc | CORRECT |
| BetBoom 0-2 Natus Vincere | 77% Natus Vinc | CORRECT |
| B8 0-2 Vitality | 80% Vitality | CORRECT |
| SINNERS 0-2 Astralis | 70% Astralis | CORRECT |
| FaZe 0-2 Vitality | 81% Vitality | CORRECT |
| BetBoom 2-1 Vitality | 83% Vitality | WRONG |
| Natus Vincere 2-1 GamerLegion | 69% Natus Vinc | CORRECT |
| Monte 2-1 The Huns | 67% Monte | CORRECT |
| HEROIC 1-2 magic | 62% HEROIC | WRONG |
| Natus Vincere 2-0 Passion UA | 74% Natus Vinc | CORRECT |
| Vitality 2-0 BC.Game | 84% Vitality | CORRECT |
Weekly digest · Top-tier CS2 matches · Week 20 · May 04 – May 10, 2026
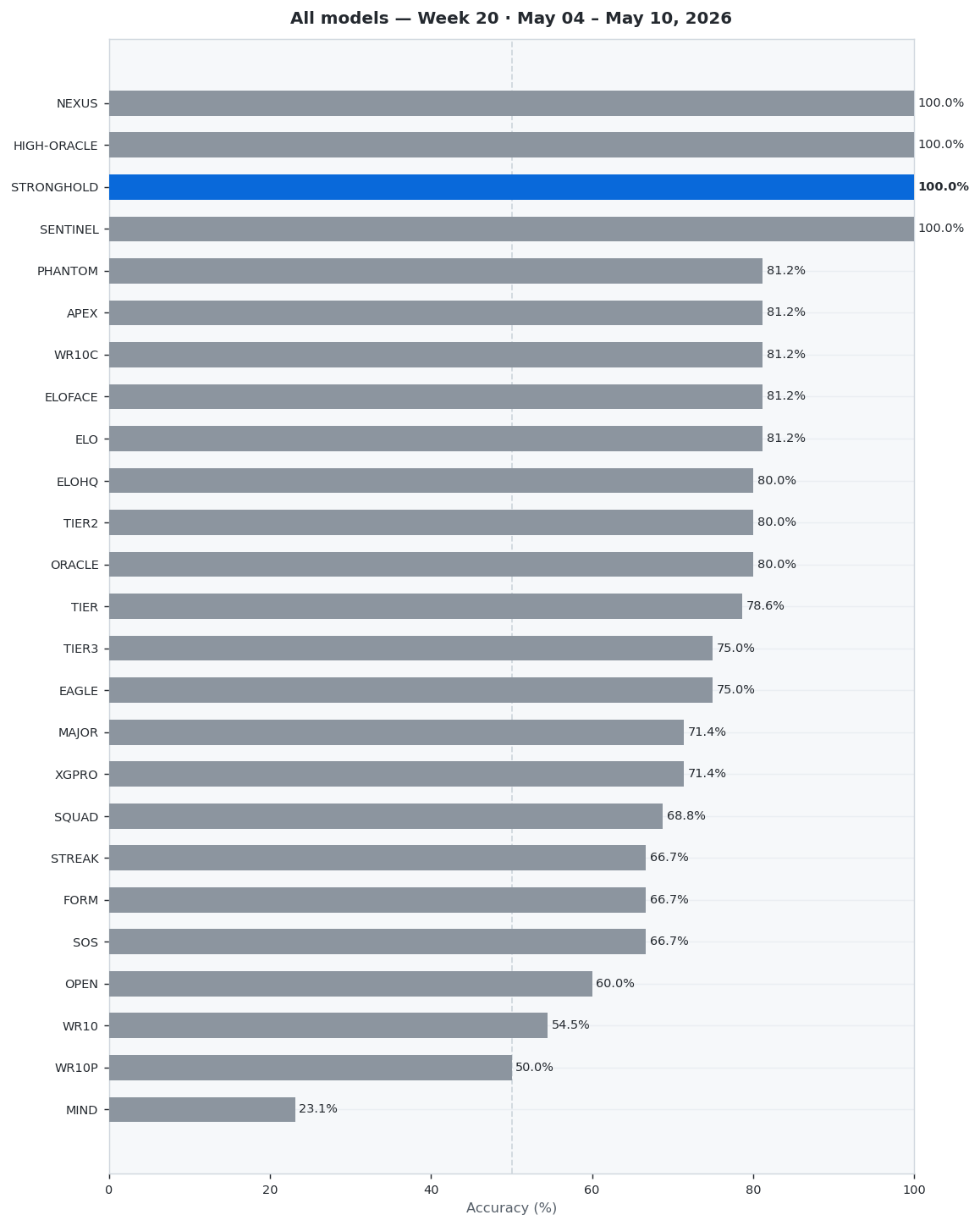
This week (Week 20 · May 04 – May 10, 2026) we analyzed 16 top-tier CS2 matches across 25 prediction models. STRONGHOLD dominated with 100.0% accuracy (8/8 correct), ahead of HIGH-ORACLE at 100.0%. STRONGHOLD achieved a Brier Score of 0.0677 and Log Loss of 0.2985.
🏆 Model of the Week: STRONGHOLD
STRONGHOLD had an outstanding week, correctly predicting 8 out of 8 matches.
STRONGHOLD showed excellent performance with 100.0% accuracy across 8 predictions (8 correct, 0 wrong).
📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.
🎮 STRONGHOLD Predictions This Week
8/8 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| Monte 2-0 magic | 65% Monte | CORRECT |
| PARIVISION 2-0 Fisher College | 75% PARIVISION | CORRECT |
| Aurora 2-0 The Huns | 76% Aurora | CORRECT |
| Falcons 2-0 K27 | 78% Falcons | CORRECT |
| Spirit 2-0 The Huns | 79% Spirit | CORRECT |
| MOUZ 2-1 Gentle Mates | 72% MOUZ | CORRECT |
| The MongolZ 2-0 magic | 76% The Mongol | CORRECT |
| G2 2-0 Fisher College | 73% G2 | CORRECT |
Weekly leaderboard · Week 19 results (May 04 – May 10, 2026) · published Week 20
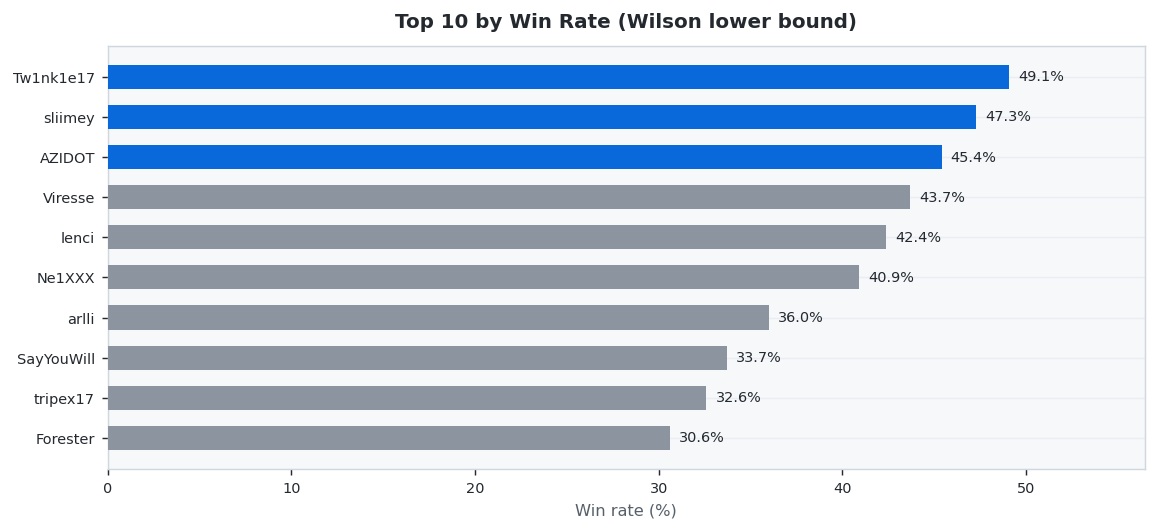
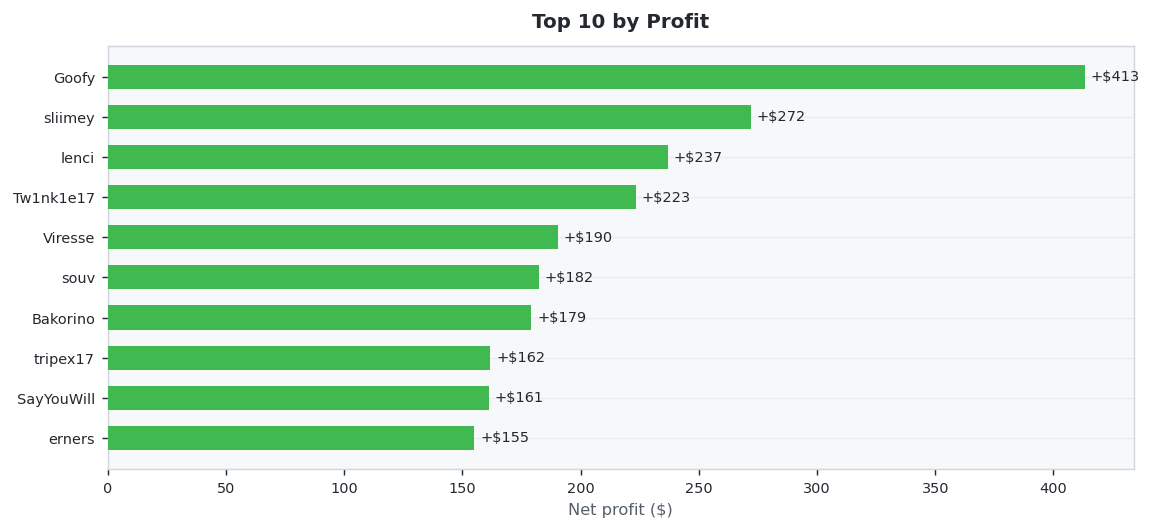
30 predictors placed 505 settled wagers this week (Week 19 results (May 04 – May 10, 2026) · published Week 20). Tw1nk1e17 led on accuracy at 49.1% Wilson, while Goofy netted +$413.28 in profit. Average accuracy across the field: 28.0%.
🎯 Win Rate Champion
Highest accuracy by Wilson lower bound (3+ settled wagers required to qualify).
💵 Profit Champion
Highest net USD return (winnings minus stakes). Green bars are winners, red are net losers.
Want next week's prize?
Top-1 in each category wins +$20. Place 3+ predictions on the match list · check the live leaderboard.
Monthly leaderboard · April 2026 results · published May 2026
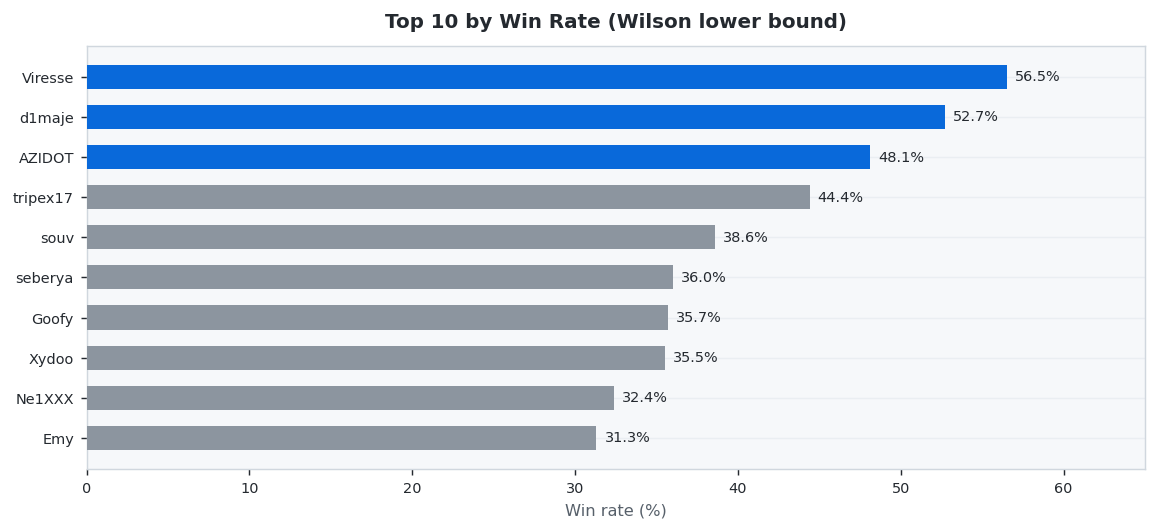
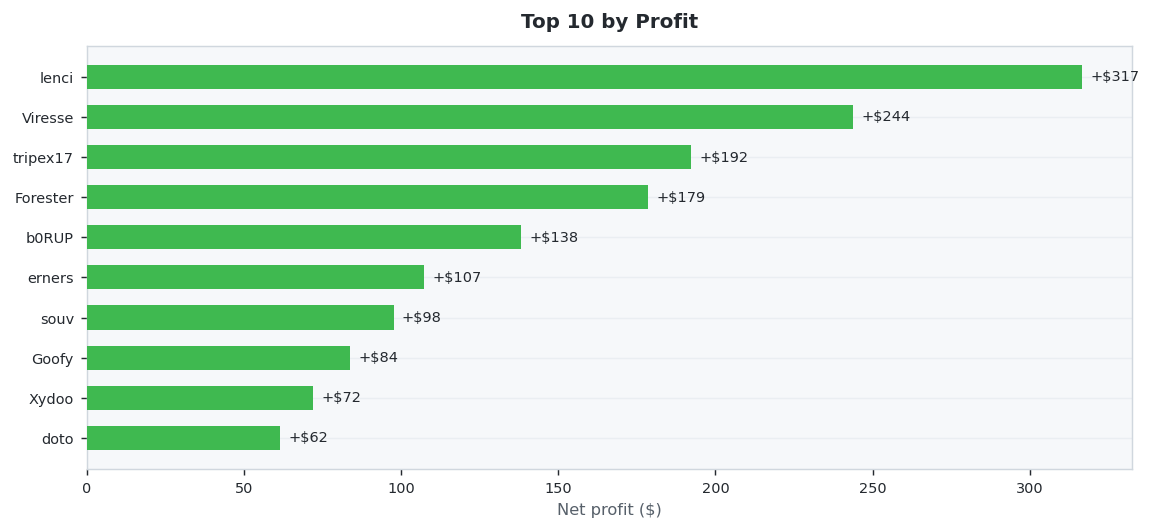
30 predictors placed 404 settled wagers this month (April 2026 results · published May 2026). Viresse led on accuracy at 56.5% Wilson, while lenci netted +$316.68 in profit. Average accuracy across the field: 27.5%.
🎯 Win Rate Champion
Highest accuracy by Wilson lower bound (3+ settled wagers required to qualify).
💵 Profit Champion
Highest net USD return (winnings minus stakes). Green bars are winners, red are net losers.
Want next month's prize?
Top-1 in each category wins +$50. Place 3+ predictions on the match list · check the live leaderboard.
Weekly leaderboard · Week 18 results (Apr 27 – May 03, 2026) · published Week 19
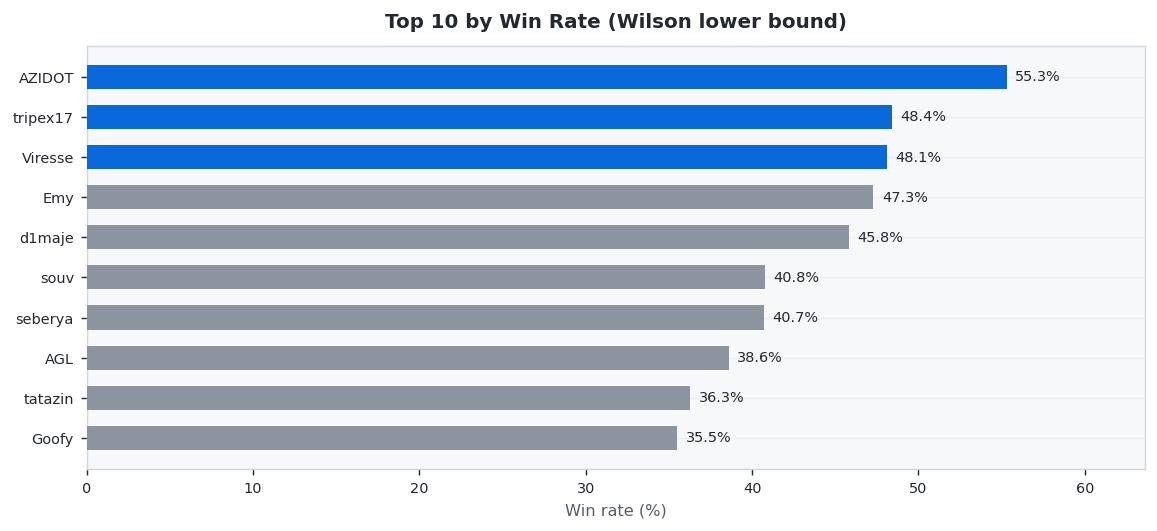
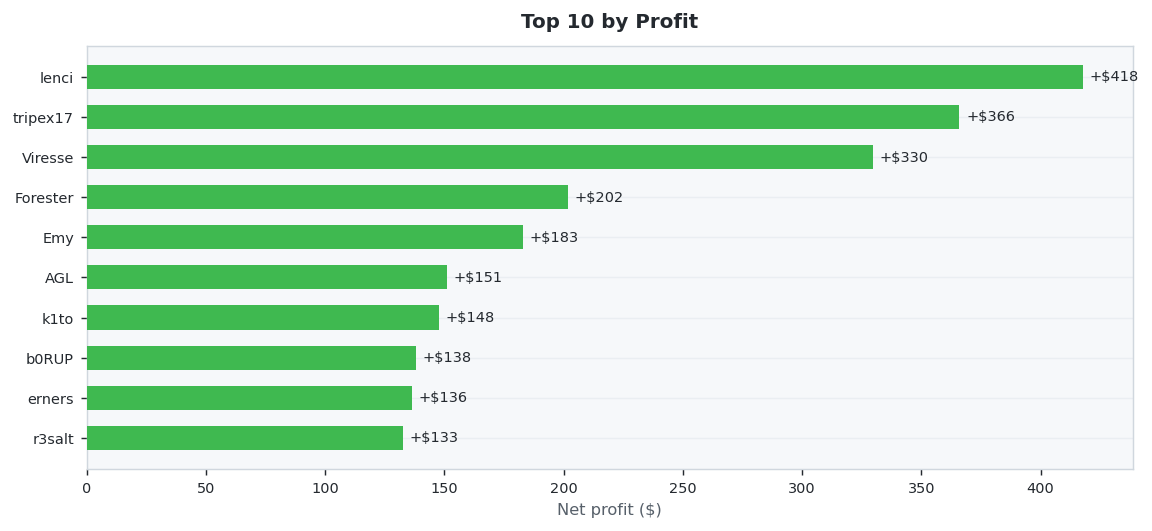
30 predictors placed 653 settled wagers this week (Week 18 results (Apr 27 – May 03, 2026) · published Week 19). AZIDOT led on accuracy at 55.3% Wilson, while lenci netted +$417.81 in profit. Average accuracy across the field: 31.2%.
🎯 Win Rate Champion
Highest accuracy by Wilson lower bound (3+ settled wagers required to qualify).
💵 Profit Champion
Highest net USD return (winnings minus stakes). Green bars are winners, red are net losers.
Want next week's prize?
Top-1 in each category wins +$20. Place 3+ predictions on the match list · check the live leaderboard.
Monthly digest · Top-tier CS2 matches · May 2026
Based on April 2026 data, we tracked 174 top-tier CS2 matches across 27 prediction models with a total of 2520 predictions. The average model accuracy was 72.3%, with a spread of 53.0% between the best and worst performing models.
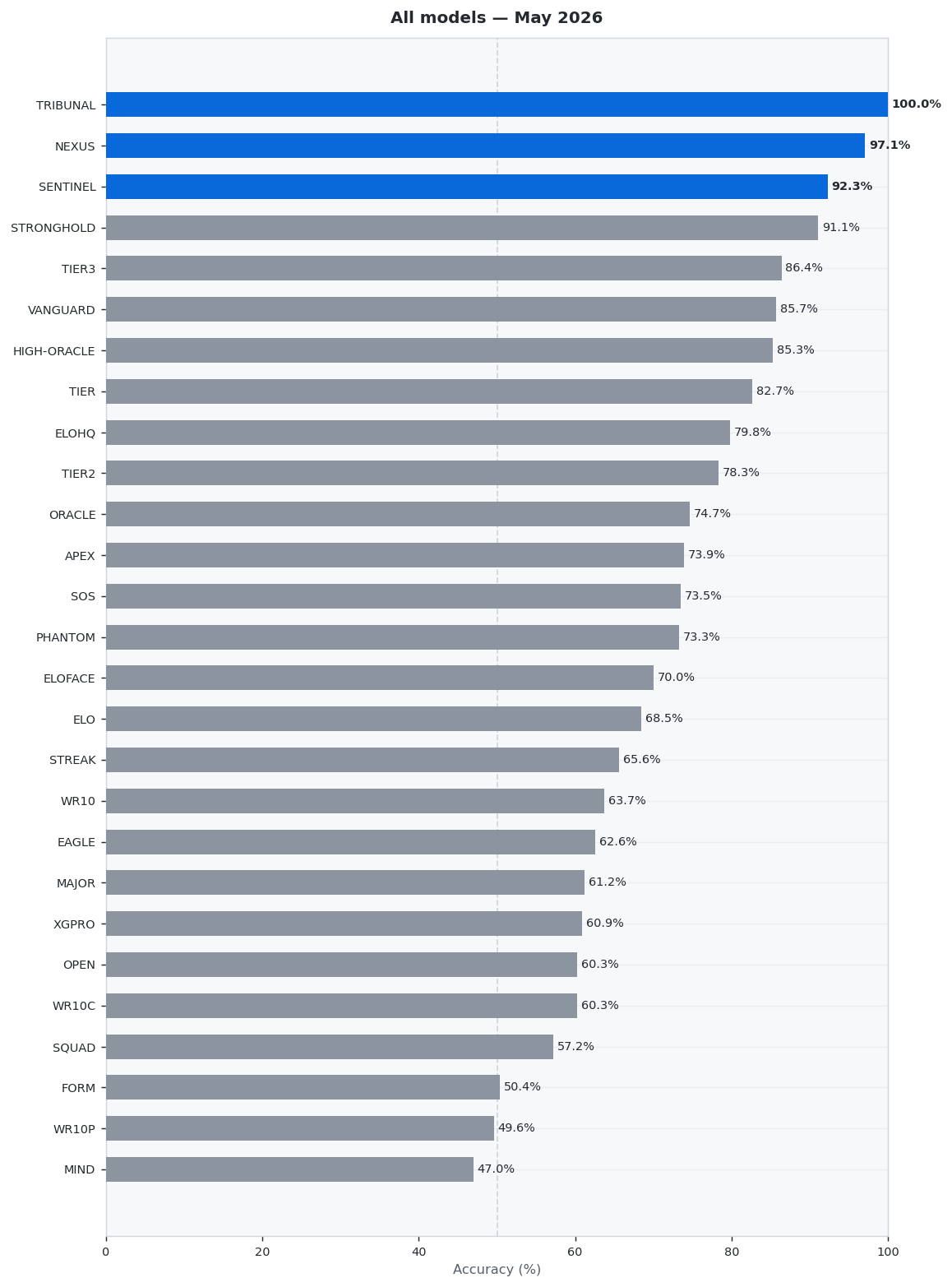
🏆 Top 3 Models of the Month
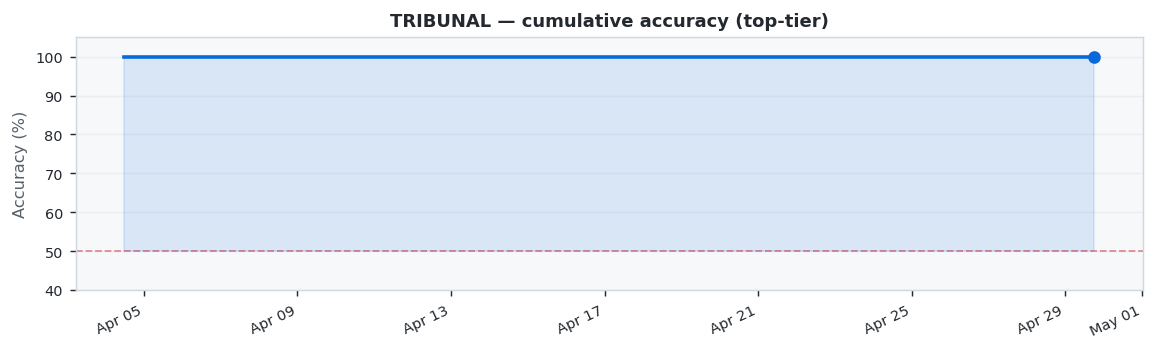
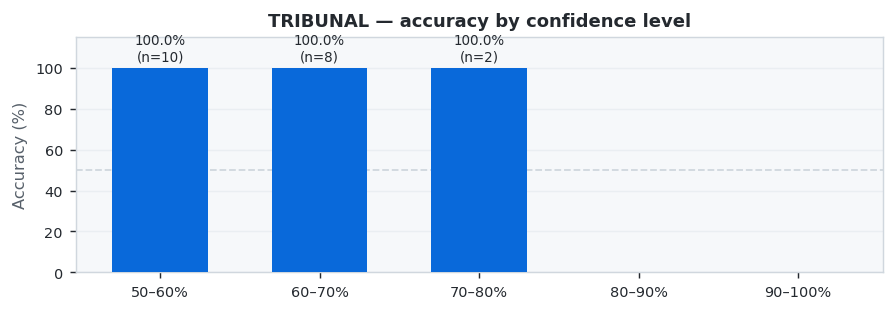
TRIBUNAL takes the top spot with 100.0% accuracy, followed by NEXUS at 97.1% and SENTINEL at 92.3%.
TRIBUNAL showed excellent performance with 100.0% accuracy across 20 predictions (20 correct, 0 wrong).
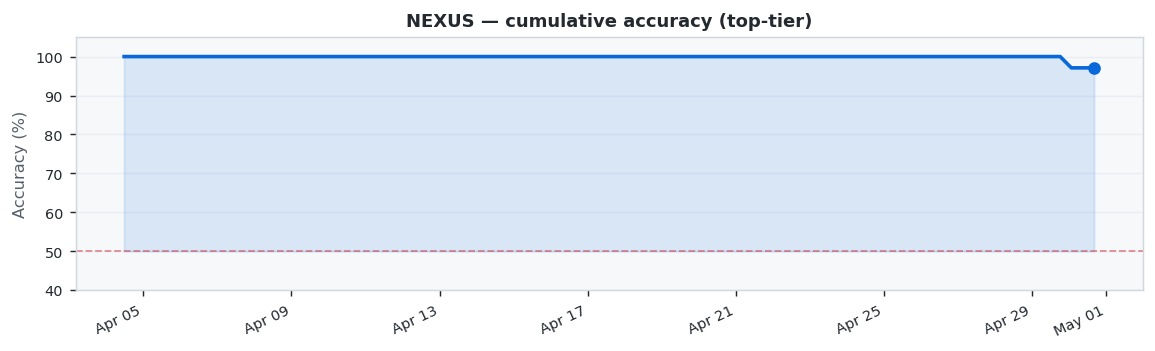
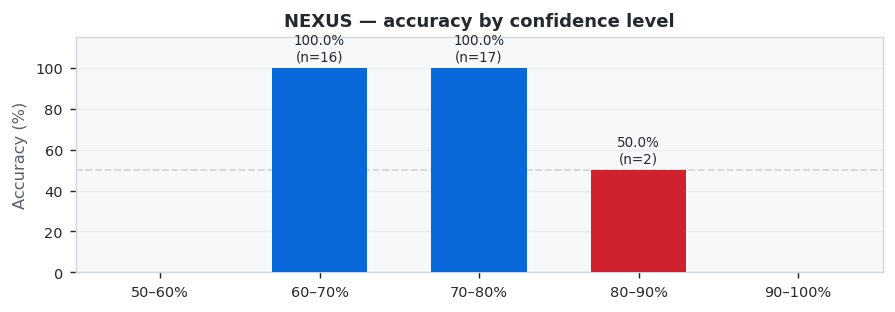
NEXUS showed excellent performance with 97.1% accuracy across 35 predictions (34 correct, 1 wrong). Best week: W14 at 100.0%, weakest: W18 at 75.0%.
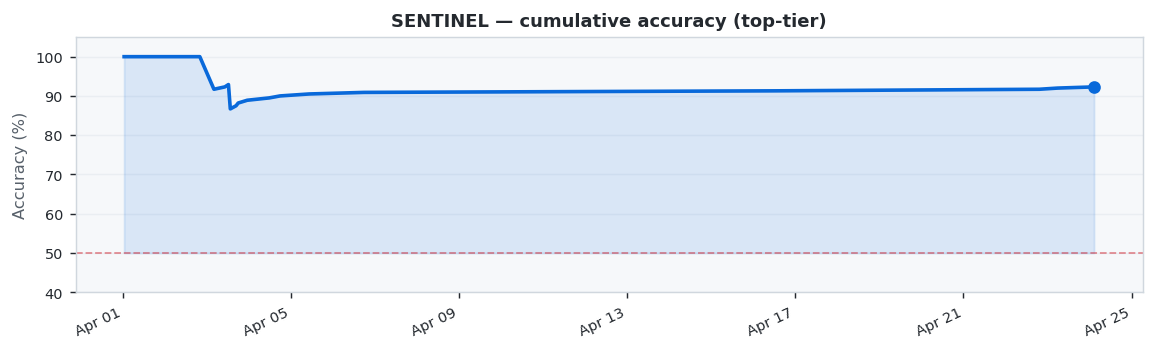
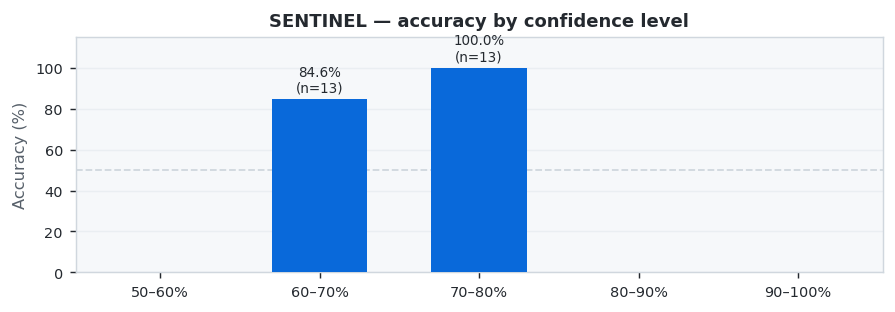
SENTINEL showed excellent performance with 92.3% accuracy across 26 predictions (24 correct, 2 wrong). Best week: W15 at 100.0%, weakest: W14 at 90.5%.
📊 Full Monthly Leaderboard
Below is the complete ranking of all models. Models highlighted in blue are in the top 3. The bar chart shows relative performance at a glance.
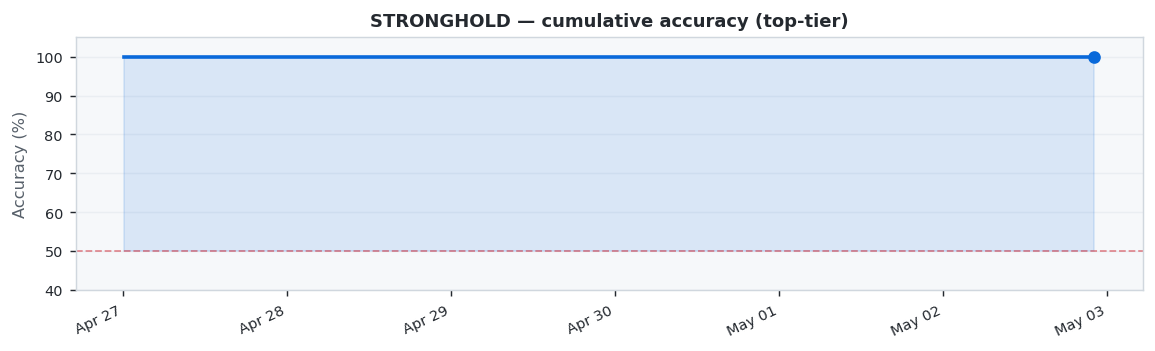
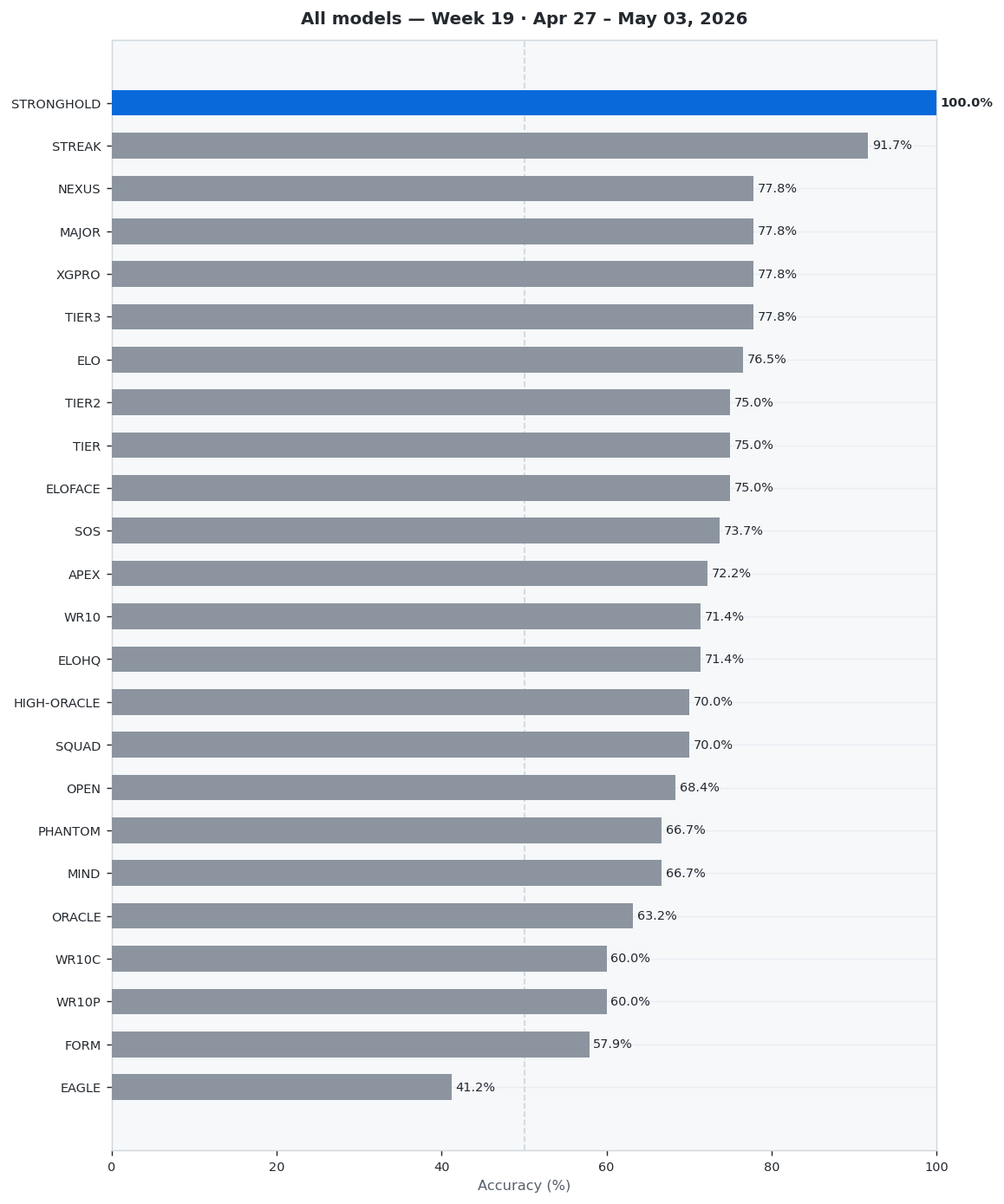
Weekly digest · Top-tier CS2 matches · Week 19 · Apr 27 – May 03, 2026
This week (Week 19 · Apr 27 – May 03, 2026) we analyzed 20 top-tier CS2 matches across 24 prediction models. STRONGHOLD dominated with 100.0% accuracy (7/7 correct), ahead of STREAK at 91.7%. STRONGHOLD achieved a Brier Score of 0.0822 and Log Loss of 0.334.
🏆 Model of the Week: STRONGHOLD
STRONGHOLD had an outstanding week, correctly predicting 7 out of 7 matches.
STRONGHOLD showed excellent performance with 100.0% accuracy across 7 predictions (7 correct, 0 wrong).
📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.
🎮 STRONGHOLD Predictions This Week
7/7 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| Vitality 2-0 GamerLegion | 79% Vitality | CORRECT |
| Natus Vincere 2-0 FaZe | 71% Natus Vinc | CORRECT |
| Natus Vincere 2-0 GamerLegion | 68% Natus Vinc | CORRECT |
| Vitality 2-1 G2 | 75% Vitality | CORRECT |
| Natus Vincere 2-0 FaZe | 71% Natus Vinc | CORRECT |
| Vitality 2-1 FUT | 76% Vitality | CORRECT |
| Legacy 3-2 9z | 62% Legacy | CORRECT |
Our first community giveaway is live. Two real CS2 knives — one for each Leaderboard category — go to the top predictors of May 2026.
Prizes

By Win Rate
★ StatTrak™ Gut Knife | Lore
Field-Tested

By Profit
★ Navaja Knife | Fade
Factory New
How to enter
Nothing extra to do — just predict matches as you normally would. Every wager you settle between May 1 00:00 UTC and May 31 23:59 UTC counts toward the May leaderboard. Whoever sits at the top of each column at the end of May wins.
Rules
- Minimum 5 settled predictions in May to qualify for either prize.
- Win Rate ranking uses the Wilson lower bound — small samples are penalised, so a lucky 3-0 streak is not enough on its own.
- Tie-breakers: total settled predictions in May, then earliest first prediction.
- If one user tops both categories, both knives go to that user.
How prizes are delivered
Within 1 day of the contest closing we will reach out to the winners. Provide your Steam trade URL and the knife is sent over Steam Trade.
Track your standing any time on the Leaderboard. Good luck.
Weekly digest · Top-tier CS2 matches · Week 18 · Apr 20 – Apr 27, 2026
This week (Week 18 · Apr 20 – Apr 27, 2026) we analyzed 13 top-tier CS2 matches across 24 prediction models. NEXUS dominated with 100.0% accuracy (9/9 correct), ahead of HIGH-ORACLE at 100.0%. NEXUS achieved a Brier Score of 0.0664 and Log Loss of 0.2942.
🏆 Model of the Week: NEXUS
NEXUS had an outstanding week, correctly predicting 9 out of 9 matches.
NEXUS showed excellent performance with 100.0% accuracy across 9 predictions (9 correct, 0 wrong).


📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.

🎮 NEXUS Predictions This Week
9/9 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| TYLOO 1-0 Sensation | 76% TYLOO | CORRECT |
| 9z 2-0 Vasco | 74% 9z | CORRECT |
| Wildcard 2-0 FRZ | 68% Wildcard | CORRECT |
| BIG 0-2 HEROIC | 68% HEROIC | CORRECT |
| Alliance 2-0 Oxuji | 69% Alliance | CORRECT |
| Legacy 2-0 Keyd Stars | 78% Legacy | CORRECT |
| 9z 2-0 Vasco | 80% 9z | CORRECT |
| Legacy 2-0 ALZON | 78% Legacy | CORRECT |
| 9z 2-0 ALKA | 80% 9z | CORRECT |
Weekly digest · Top-tier CS2 matches · Week 17 · Apr 13 – Apr 20, 2026
This week (Week 17 · Apr 13 – Apr 20, 2026) we analyzed 30 top-tier CS2 matches across 25 prediction models. NEXUS dominated with 100.0% accuracy (10/10 correct), ahead of STRONGHOLD at 100.0%. NEXUS achieved a Brier Score of 0.0884 and Log Loss of 0.3524.
🏆 Model of the Week: NEXUS
NEXUS had an outstanding week, correctly predicting 10 out of 10 matches.
NEXUS showed excellent performance with 100.0% accuracy across 10 predictions (10 correct, 0 wrong).


📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.

🎮 NEXUS Predictions This Week
10/10 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| Spirit 0-3 Vitality | 71% Vitality | CORRECT |
| FURIA 0-2 Vitality | 68% Vitality | CORRECT |
| Vitality 2-0 Natus Vincere | 72% Vitality | CORRECT |
| HEROIC 1-0 illwill | 73% HEROIC | CORRECT |
| RED Canids 1-2 Spirit | 68% Spirit | CORRECT |
| FURIA 2-0 Passion UA | 71% FURIA | CORRECT |
| Legacy 1-2 MOUZ | 72% MOUZ | CORRECT |
| 3DMAX 0-2 Falcons | 70% Falcons | CORRECT |
| Spirit 2-0 Liquid | 68% Spirit | CORRECT |
| Gentle Mates 1-2 G2 | 71% G2 | CORRECT |
Weekly digest · Top-tier CS2 matches · Week 16 · Apr 06 – Apr 13, 2026
This week (Week 16 · Apr 06 – Apr 13, 2026) we analyzed 50 top-tier CS2 matches across 25 prediction models. NEXUS dominated with 100.0% accuracy (12/12 correct), ahead of STRONGHOLD at 100.0%. NEXUS achieved a Brier Score of 0.0893 and Log Loss of 0.3546.
🏆 Model of the Week: NEXUS
NEXUS had an outstanding week, correctly predicting 12 out of 12 matches.
NEXUS showed excellent performance with 100.0% accuracy across 12 predictions (12 correct, 0 wrong).


📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.

🎮 NEXUS Predictions This Week
12/12 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| Spirit 0-3 Vitality | 71% Vitality | CORRECT |
| FURIA 0-2 Vitality | 68% Vitality | CORRECT |
| Vitality 2-0 Natus Vincere | 72% Vitality | CORRECT |
| HEROIC 1-0 illwill | 73% HEROIC | CORRECT |
| RED Canids 1-2 Spirit | 68% Spirit | CORRECT |
| FURIA 2-0 Passion UA | 71% FURIA | CORRECT |
| Legacy 1-2 MOUZ | 72% MOUZ | CORRECT |
| 3DMAX 0-2 Falcons | 70% Falcons | CORRECT |
| Spirit 2-0 Liquid | 68% Spirit | CORRECT |
| Gentle Mates 1-2 G2 | 71% G2 | CORRECT |
| 3DMAX 0-2 The MongolZ | 69% The Mongol | CORRECT |
| BC.Game 2-1 Voca | 70% BC.Game | CORRECT |
We've added 2 new consensus models to CS2PREDICT: NEXUS and TRIBUNAL. Both were discovered through live data analysis — optimizing over real pre-match predictions with zero data leakage.
What Are Consensus Models?
Unlike base models that compute predictions independently from raw team stats, consensus models act as filters on top of existing models. They only make a prediction when multiple models agree with high confidence. The result: fewer predictions, but significantly higher accuracy.
The New Models
NEXUS — APEX + ORACLE both >65% same direction
The sharpest double confirmation on the site. NEXUS only activates when both APEX and ORACLE are strongly aligned — meaning two independent multi-factor models see the same outcome with high conviction. In backtesting on live top-tier matches: 100% accuracy on 12 predictions.
TRIBUNAL — OPEN + PRO + ORACLE all >55% same direction
A three-model consensus built around ORACLE as the anchor, confirmed by both the OPEN and PRO predictors. These three models use different feature sets — when all three agree, the signal is remarkably consistent. In backtesting on live top-tier matches: 100% accuracy on 11 predictions.
Important Context
The 100% accuracy figures are from a small sample of top-tier matches — treat them as promising early signals, not guarantees. Both models will fire rarely by design: NEXUS requires two models at 65%+ confidence, TRIBUNAL requires three at 55%+. Expect 1–3 predictions per week on top-tier matches.
As live data accumulates over the coming weeks, you'll see real accuracy statistics on each model's page.
NEXUS and TRIBUNAL are available for Pro subscribers.
Weekly digest · Top-tier CS2 matches · Week 15 · Mar 30 – Apr 06, 2026
This week (Week 15 · Mar 30 – Apr 06, 2026) we analyzed 193 top-tier CS2 matches across 27 prediction models. NEXUS dominated with 100.0% accuracy (22/22 correct), ahead of TRIBUNAL at 100.0%. NEXUS achieved a Brier Score of 0.0861 and Log Loss of 0.3457.
🏆 Model of the Week: NEXUS
NEXUS had an outstanding week, correctly predicting 22 out of 22 matches.
NEXUS showed excellent performance with 100.0% accuracy across 22 predictions (22 correct, 0 wrong).


📊 Full Rankings This Week
Complete model performance for the week. The leader is highlighted.

🎮 NEXUS Predictions This Week
22/22 correct predictions on top-tier matches.
| MATCH | PREDICTION | RESULT |
|---|---|---|
| Spirit 0-3 Vitality | 71% Vitality | CORRECT |
| FURIA 0-2 Vitality | 68% Vitality | CORRECT |
| Vitality 2-0 Natus Vincere | 72% Vitality | CORRECT |
| HEROIC 1-0 illwill | 73% HEROIC | CORRECT |
| RED Canids 1-2 Spirit | 68% Spirit | CORRECT |
| FURIA 2-0 Passion UA | 71% FURIA | CORRECT |
| Legacy 1-2 MOUZ | 72% MOUZ | CORRECT |
| 3DMAX 0-2 Falcons | 70% Falcons | CORRECT |
| Spirit 2-0 Liquid | 68% Spirit | CORRECT |
| Gentle Mates 1-2 G2 | 71% G2 | CORRECT |
| 3DMAX 0-2 The MongolZ | 69% The Mongol | CORRECT |
| BC.Game 2-1 Voca | 70% BC.Game | CORRECT |
| paiN 3-1 Gaimin Gladiators | 72% paiN | CORRECT |
| PARIVISION 2-0 FOKUS | 74% PARIVISION | CORRECT |
| 3DMAX 2-1 Voca | 74% 3DMAX | CORRECT |
| FaZe 2-0 CYBERSHOKE | 68% FaZe | CORRECT |
| PARIVISION 2-1 Legacy | 69% PARIVISION | CORRECT |
| paiN 2-1 ShindeN | 81% paiN | CORRECT |
| GamerLegion 0-2 BetBoom | 68% BetBoom | CORRECT |
| Astralis 2-0 MIBR | 68% Astralis | CORRECT |
| B8 2-0 Wildcard | 68% B8 | CORRECT |
| NRG 2-0 Voca | 77% NRG | CORRECT |
What Are Predictions on CS2PREDICT?
CS2PREDICT lets you test your CS2 knowledge by predicting match outcomes. Use your account balance to place predictions on upcoming matches and earn payouts when you're right.
How It Works
- Find a match — browse upcoming matches on the main page. Look for matches with the "PREDICT" buttons visible.
- Choose your team — click PREDICT Team A or PREDICT Team B
- Set your amount — enter how much you want to predict (min $1). Free tier: up to $50. Pro tier: up to $500.
- Confirm — your prediction is locked in and your balance is deducted
- Wait for results — when the match ends, payouts are calculated automatically
The Prediction Pool
All predictions on a match go into a shared pool. Below each match you'll see:
- Pool: $X — total amount predicted by all users
- X vs Y — how the pool is split between the two teams
- Odds (x1.5, x2.3, etc.) — your potential payout multiplier
How Odds Work
Odds are calculated from the pool distribution, not from AI predictions:
- If 80% of the pool is on Team A, Team A pays x1.25 (low payout, popular pick)
- Team B would pay x5.0 (high payout, underdog pick)
- The less popular the pick, the higher the potential payout
Odds update in real-time as more users place predictions.
Payouts
When the match completes:
- Correct prediction — you receive your stake multiplied by the odds. Example: $10 at x2.0 odds = $20 payout ($10 profit).
- Wrong prediction — you lose your stake. It goes to the winners' pool.
- Payouts are processed automatically within minutes of the match result.
Prediction Locking
Predictions lock when the match starts (goes LIVE). You cannot change or cancel a prediction after it's locked. Plan ahead — place your predictions before match start.
Your Balance
Check your balance in the top-right corner of the site. To add funds:
- Go to Balance page
- Send USDT (TRC-20) to the provided wallet address
- Deposits are detected automatically (checked every 5 minutes)
Subscription Tiers
| Free | Basic models visible, predictions not available (subscribe to predict) |
| Basic | More models unlocked, predictions up to $50 |
| Pro | All models + detailed analytics, predictions up to $500 |
See Subscription page for current pricing.
Tips
- Check model consensus before predicting — when most AI models agree, the outcome is more likely
- Watch the odds — sometimes the crowd is wrong, and the underdog pays well
- Start small — learn the system with $1-5 predictions before going bigger
- Diversify — don't put everything on one match
Where to See Your Predictions
Your active predictions appear on each match card (below the pool info). Past results are visible on the Results page — check which of your predictions were correct.
How to Use Match Predictions
Every upcoming match on CS2PREDICT shows predictions from multiple AI models. This guide explains how to read the match page and make the most of the data.
The Match Card
Each match card on the main page shows:
- Teams — with logos, HLTV rankings, and clickable names leading to team profiles
- Lineups — 5 players per team with photos, each clickable to their player profile
- Time — match start time (converted to your local timezone)
- Event — tournament name with star rating (more stars = bigger event)
- Predictions — model outputs shown as percentage cards on the right
Reading the Prediction Cards
Each small card represents one AI model's prediction:
- Top label — model name (e.g., ORACL, APEX, TIER)
- Percentage — how confident the model is in the predicted winner (always shown as the higher side, e.g., 67%)
- Bottom label — which team the model predicts to win
- Lock icon — model requires Basic or Pro subscription
Color Coding
Prediction percentages are color-coded:
- Green (70%+) — high confidence, the model sees a clear advantage
- Yellow (60-70%) — moderate confidence, edge exists but upset possible
- Red/Gray (50-60%) — low confidence, close match
Predictions between 48-52% are hidden (shown as 50/50) because they carry no useful signal.
The Consensus Bar
Below the team names, a colored bar shows the overall consensus across all models:
- If the bar is mostly on one side (e.g., 70/30), most models agree — stronger signal
- If it's close to 50/50, models disagree — uncertain match, proceed with caution
Match Detail Page
Click any match to see the full detail page with:
- All model predictions — not just the top 15
- Model accuracy badges — how accurate each model has been historically
- Player lineups — clickable to individual player profiles with tactical radars
- Team links — clickable to team pages with roster analysis and match history
- Wager pool — community predictions with odds
After the Match
Once a match completes:
- The result appears on the Results page
- Each prediction is scored — correct (green check) or wrong (red cross)
- Model accuracy on the leaderboard updates immediately
- ELO ratings recalculate, improving future predictions
Tips for Best Results
- Follow consensus — when 15+ models agree, they're usually right
- Check the leaderboard — not all models are equal, some are consistently better
- Watch for model disagreement — if TIER says 75% Team A but MIND says 60% Team B, the match is genuinely uncertain
- Consider the tier — we only show predictions for Top & Major matches where accuracy is highest
- Look at player profiles — check the tactical radar to understand each team's playstyle
Overview
CS2PREDICT uses multiple independent AI models to predict the outcome of professional CS2 matches. Each model analyzes different aspects of the game — from pure skill ratings to psychological momentum to team chemistry. No single model is perfect, but together they provide a comprehensive view of each matchup.
How predictions are generated
When a new match appears on HLTV, our system automatically:
- Identifies both teams and their current rosters (5 players each)
- Loads player history — recent match stats, ratings, form trends from our database
- Computes 50+ features per match — ELO ratings, momentum, tilt, head-to-head record, roster stability, strength of schedule, and more
- Runs all models — each model outputs a probability (e.g., "Team A has 67% chance to win")
- Displays results — predictions refresh every 5 minutes as new data arrives
Model categories
| ELO family ELO, ELOHQ, ELOFACE, TIER, TIER2, TIER3 | Skill-based ratings. ELO tracks overall team strength. TIER variants focus on top-30 teams where data is richest. ELOFACE adds training activity signals. |
| Form & H2H OPEN, PRO, MAJOR, FORM | Combine HLTV ranking with recent form, head-to-head history, and match format. PRO and MAJOR are tuned for high-stakes events. |
| Psychology MIND, STREAK | Track mental state — tilt from losing streaks, momentum from winning streaks, recovery patterns after losses. |
| Player-based SQUAD, SOS, WR10 | Analyze individual player performance. SQUAD uses per-player ratings. SOS factors in opponent strength. WR10 focuses on win rate against top-10 teams. |
| Ensemble APEX, PHANTOM, ORACLE, EAGLE | Combine multiple signals. ORACLE blends ELO + form + tilt + SOS. EAGLE adds win rate data. These combine multiple signals for higher accuracy. |
What happens after a match
Results are checked every 10 minutes. When a match completes:
- Each model's prediction is scored as correct or incorrect
- ELO ratings update based on the result (winners gain, losers drop)
- Model accuracy on the leaderboard updates in real-time
- All upcoming matches are re-predicted with updated ratings
Prediction tiers
We classify matches into tiers based on team rankings and tournament importance:
- Top — matches between ranked teams at major events. Best prediction accuracy.
- Major — major qualifier and playoff matches.
- Other — lower-tier matches. Shown as schedule only, without predictions, because accuracy drops to ~50%.
Data sources
All data comes from HLTV.org — the authoritative source for professional CS2 statistics. We collect match results, player box scores, team rankings, and tactical profiles (Rating 3.0 radar). Data refreshes every 5 minutes for matches and daily for player profiles.
The Tactical Radar
Each player profile on CS2PREDICT shows a tactical radar with 7 metrics scored from 0 to 100. These come from HLTV's Rating 3.0 system and represent the player's style and strengths over the past 3 months.
Metrics explained
| Firepower | Raw fragging power — kills per round, damage output, multi-kills. High firepower = the player wins aim duels and gets kills consistently. |
| Entrying | How often the player enters sites first on T-side. High entrying = aggressive entry fragger who creates space for the team. Usually dies first but opens rounds. |
| Trading | How well the player trades kills — getting a kill right after a teammate dies. High trading = good team player who ensures no death goes unpunished. |
| Opening | Success rate in opening duels — the first fight of each round. High opening = wins the critical first engagement, giving the team a numbers advantage. |
| Clutching | Win rate in 1vN situations (1v1, 1v2, 1v3, etc.). High clutching = calm under pressure, can close out rounds alone. The "clutch factor." |
| Sniping | AWP proficiency — kill rate and impact with the sniper rifle. High sniping = dedicated AWPer. Most players score 0 here; only AWPers score high. |
| Utility | Effectiveness with grenades — flash assists, smoke placements, HE/molotov damage. High utility = structured, tactical player who helps the team through utility, not just aim. |
Reading team compositions
A well-rounded team typically has:
- 1-2 high Firepower players (star fraggers)
- 1 high Entrying player (entry fragger)
- 1 high Sniping player (AWPer)
- 1-2 high Utility players (support/IGL)
Teams with balanced radar across all players tend to be more consistent. Teams with one extremely high firepower player and low stats elsewhere are "star-dependent" — if the star underperforms, the team collapses.
Example
See a live player profile: ZywOo — one of the highest-rated players in CS2 history. Notice his extreme Firepower and Sniping scores.
Data freshness
Tactical profiles update daily at 02:00 UTC. The metrics reflect the last 3 months of competitive play on HLTV.